Can a search engine crawl your site? Are all of the pages allowed to be crawled? If not, which URLs are not being accessed by search engines, and why does it happen?
This can be influenced by editing indexation directives on your site. First, in robots.txt file, and secondly, in meta robots tags in the HTML <head> tag or in the HTTP header of each page. Before analyzing and fixing issues, let me tell you about the basics of crawling and indexing.
Crawling
Before a search engine lands on your website, it inspects robots.txt file. First of all, it checks to ensure all pages of your site are allowed to crawl. Basically, you can add any pages or parts of a site you don’t want being crawled. That means if you disallow pages with the URL path /user/, the engine will skip them.
Developers and SEO specialists usually use robots.txt for optimizing a crawl budget. It’s really important to secure the budget only for large websites with billions of URLs. Small and average websites with hundreds or thousands of URLs shouldn’t have any problems with crawling, therefore you may not need to use robots.txt file for your website at all.
Indexing
After a search engine visits a page, it checks meta robots directives. These directives naturally allow indexing and following the page. But if the need arises, you can change it and instruct the search engine to do otherwise by using meta robots directives noindex and nofollow. In that case, the search engine will respect these directives, and your page will not be indexed or followed.
With Spotibo, you can get automatic results for these crawling and indexing issues:
- Pages are blocked by robots.txt
- Pages include noindex tag
- Pages include nofollow tag
- CSS is blocked by robots.txt
- JavaScript is blocked by robots.txt
Pages are blocked by robots.txt
Why does the error occur?
There are pages disallowed in robots.txt, indicating to search engine crawlers that these URLs can’t be crawled.
How does it impact SEO?
High importance: ★★★
If crawlers aren’t allowed to crawl a URL and to request its content, the content and links on the URL will not be parsed. Therefore, a page will not be able to rank, and any authority signals will be lost.
Organic traffic coming to pages disallowed in robots.txt can decrease to zero. Careless use of robots.txt file can cause the whole website to drop in the SERP.
How to fix it
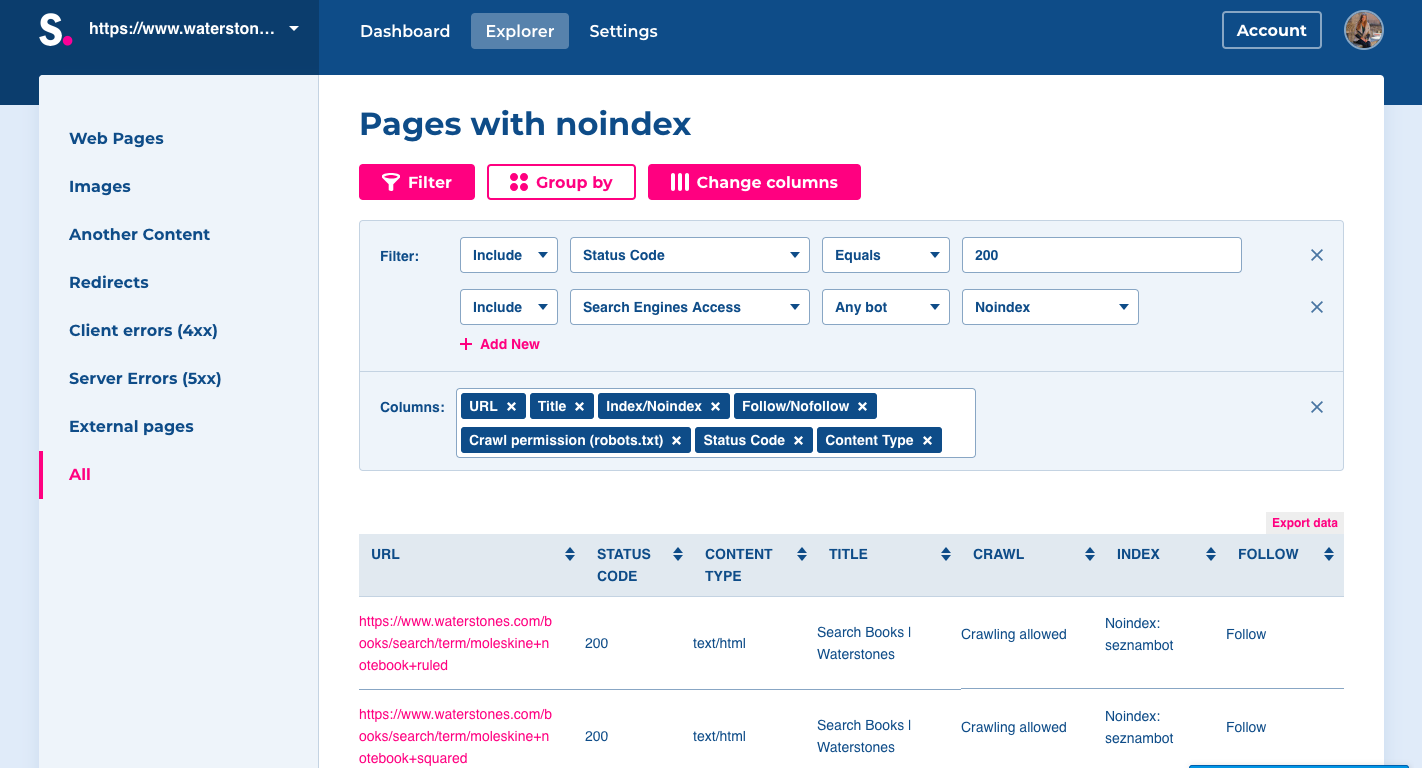
- At Dashboard, open issue Pages are blocked by robots.txt.
- After clicking, you will land on Explorer section, where you can filter and group your data as needed.
- After opening the table with disallowed URLs, see if there are any pages you want to have available for the users. If so, allow them in robots.txt file.
[box type=”download”]
An example of using robots.txt:
Robots.txt file is located on http://yourdomain.com/robots.txt. It contains information in this form:
|
Name of a search engine bot to which apply directives. “*” means to all engines. |
User-agent: * |
|
URLs you want to block crawlers from accessing, for example all, admin pages at www.domain.com/admin/ |
Disallow: /admin/ |
|
Other URLs to disallow. For example, all pages with “search” parameters applying to a site. |
Disallow: *?search |
Check for more on how to work with directives and syntax such as “*” and “$,” and avoid critical errors in robots.txt file. [/box]
Advanced tip:
If Spotibo detected pages on your site as disallowed in robots.txt, double-check if there is a reason for that.
You can use disallow directives in robots.txt file if you need to reduce crawl budget or if you want to hide some pages, such as private, temporary, code and script pages.
Examples when things can go wrong:
- If you add to robots.txt Disallow: /, (your homepage can’t be crawled)
- If you disallow an old domain when migrating to a new domain
- If you disallow redirected pages
Using robots.txt is not simple, though. That is a job for an SEO specialist or developer. Many times, a better solution can be using noindex, canonical or redirect. Therefore, consult it before making any changes.
Note: You should not use robots.txt to hide your web pages from search results, because your page could get into search results, anyway. If you want to block the page from search results, use noindex meta robots directives.
Pages with noindex tag
Why does the error occur?
There are pages containing noindex in robots meta tag or in X-Robots-Tag HTTP header. These tags indicate to search engine crawlers that these URLs shouldn’t be indexed, therefore, they will not be shown in SERPs.
By default, a web page is set to “index.” “Noindex” attributes on the found pages were probably added manually, so maybe you have a reason to use them with respect to SEO.
How does it impact SEO?
High importance: ★★★
All pages with noindex attribute are left out of the index of search engines. Because these pages are not shown in search engine results at all, it can cause a drop in organic traffic.
How to fix it
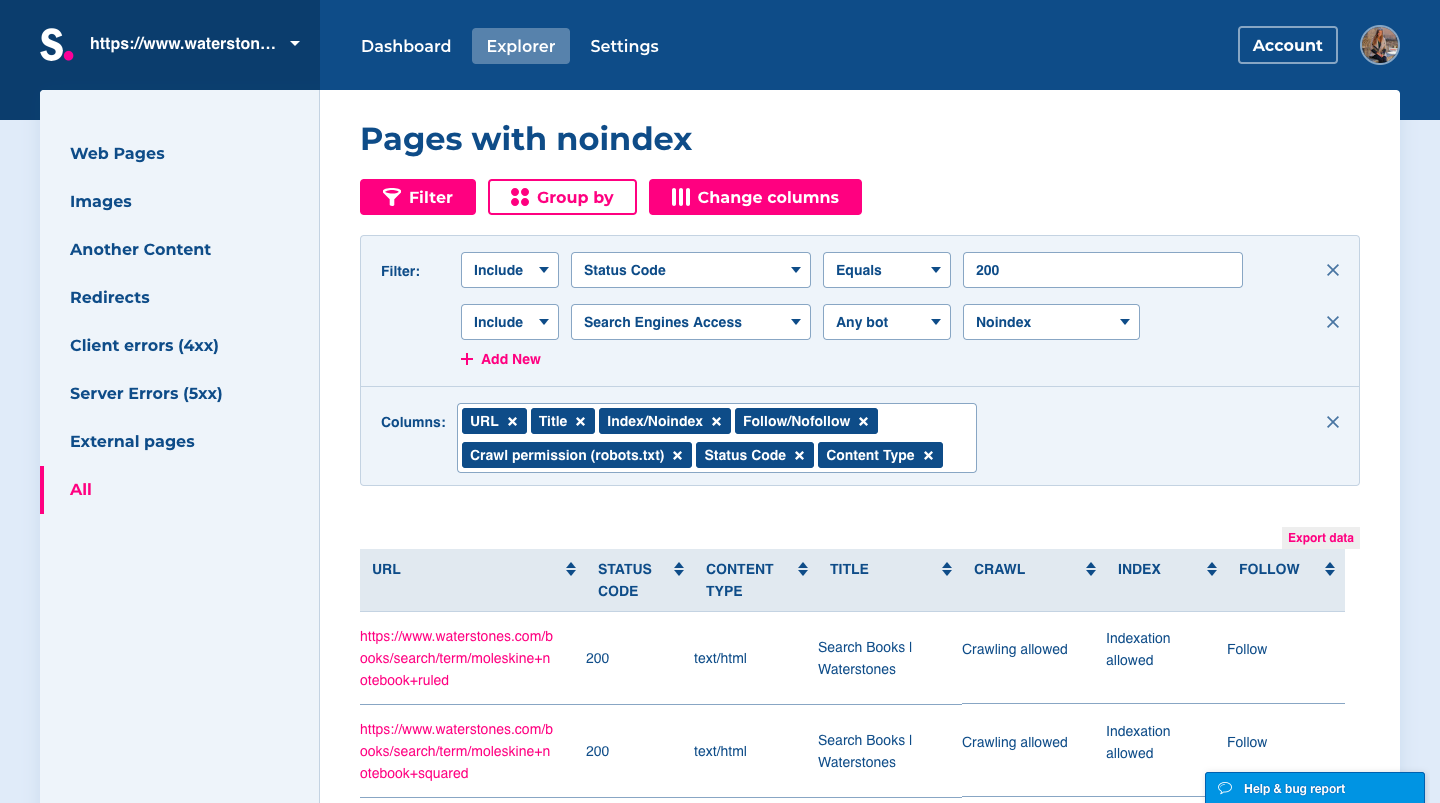
- At Dashboard, open issue Pages with noindex tag.
- After clicking, you will land on Explorer section, where you can filter and group the URLs as you need.
- After opening the table with URLs containing noindex, check all of these pages regarding your internal website structure. Look if there are any pages you want to make accessible for users. If there are any pages or parts of your site that should be accessible from search engines to visitors, you need to allow indexing by editing the tag in meta robots or in the HTTP header.
[box type=”download”]An example of using meta noindex:
To tell search engines to index your page, simply add the following to the </head> section of the HTML code of the particular page:
<meta name=”robots” content=”index, follow”>
On the other hand, if you realize that more of your pages than you found need to be disallowed to index, add this tag to the particular page:
<meta name=”robots” content=”noindex, follow”>
Alternatively, the index and noindex attributes can also be used in an X-Robots-Tag in the HTTP header:
X-Robots-Tag: index or X-Robots-Tag: noindex [/box]
Note: If you want to prevent page indexing, do not use disallow in a robots.txt file. If the page is blocked via a robots.txt file, a search engine can’t crawl and see the noindex attribute, so it doesn’t know that they’re not supposed to leave the page out of the index.
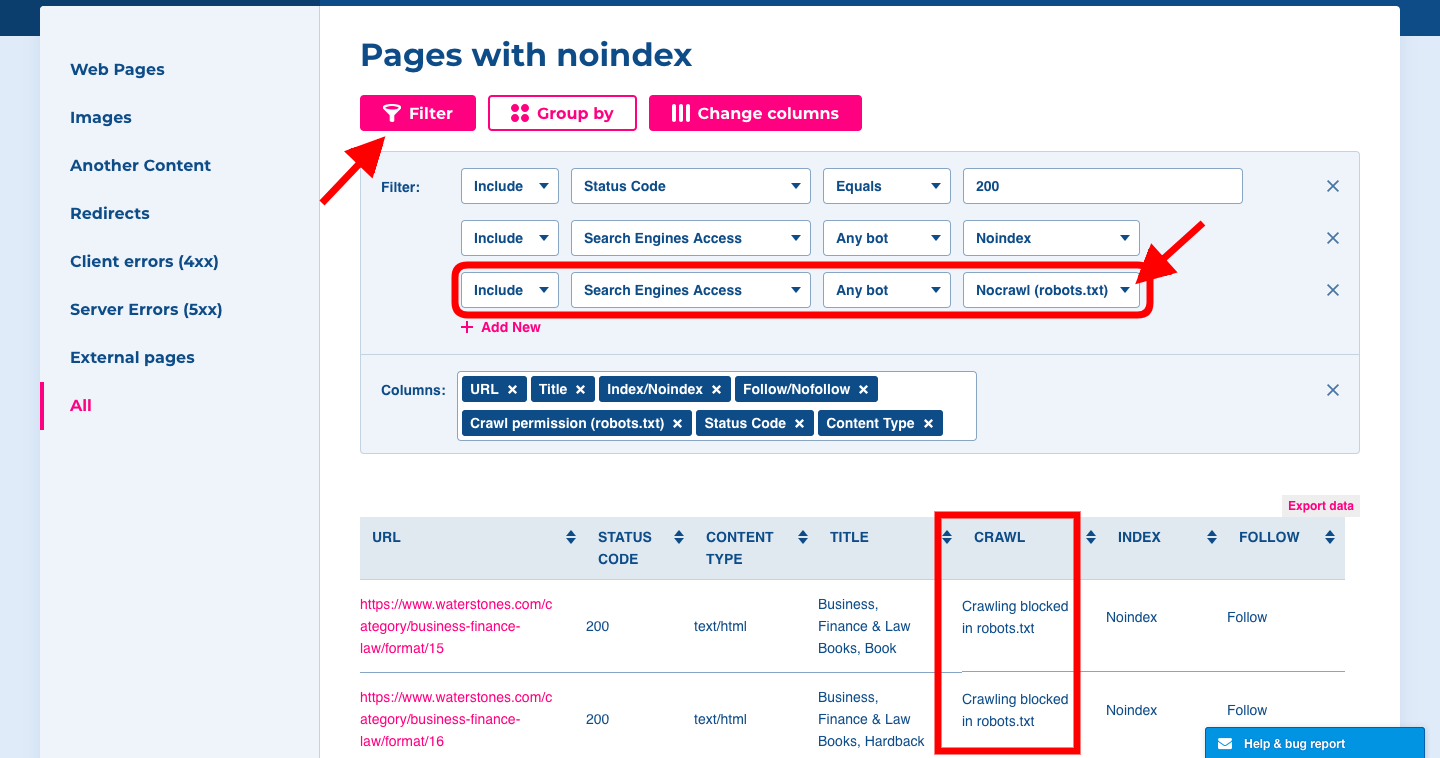
To be sure, check it at Spotibo:
- Add Filter.
- Include Search Engine Access for Any bot Nocrawl (robots.txt).
Pages with nofollow tag
Why does the error occur?
There are pages containing “nofollow” in robots meta tags or in X-Robots-Tag HTTP header, which indicates to search engine crawlers that links on these URLs shouldn’t be followed.
Note: Use of nofollow tag is common for both HTML pages and for links. But in this particular issue, we are referring only to meta robots directives of an HTML page.
How does it impact SEO?
Mid-high importance: ★★☆
If you use the nofollow attribute on a page, the search engines don’t go through the links, and they don’t pass any link juice. As the search engines don’t follow the links further, they don’t crawl the linked pages, and if there are no other internal or external links pointing at those pages, so they won’t be indexed. Careless use of nofollow can cause a drop of the whole website in the SERP.
How to fix it
- At Dashboard, open issue Pages with nofollow tag.
- You will land on the Explorer table, where you can filter and group the URLs.
- Check all the pages containing nofollow regarding your internal website structure. If there are any pages you don’t want to be marked with nofollow attribute, rewrite them to follow.
[box type=”download”]An example of using meta nofollow:
To tell search engines to follow your page, simply add the following to the </head> section of the HTML code of the particular page:
<meta name=”robots” content=”index, follow”>
On the other hand, if you realize that more of your pages than you found need to be disallowed to follow, adding this tag to the particular page:
<meta name=”robots” content=”index, nofollow”>
Alternatively, the follow and nofollow attributes can be used also in an X-Robots-Tag in the HTTP header:
X-Robots-Tag: follow or X-Robots-Tag: nofollow [/box]
Note: A nofollow won’t prevent the linked page from being crawled completely; it just prevents it from being crawled through that specific link. The link to a page can appear on the other internal pages, or even on external websites, so they still can be found by search engines and indexed. A nofollow link won’t remove a page from the index. For that, instead use noindex attribute.
CSS is blocked by robots.txt
Why does the error occur?
CSS files are disallowed in robots.txt file on your website.
How does it impact SEO?
Medium-high importance: ★★☆
By disallowing CSS in robots.txt, you’re preventing search engine crawlers from rendering all the content and seeing if your website works properly. Crawlers can’t fully understand your website, which might result in lower rankings.
How to fix it
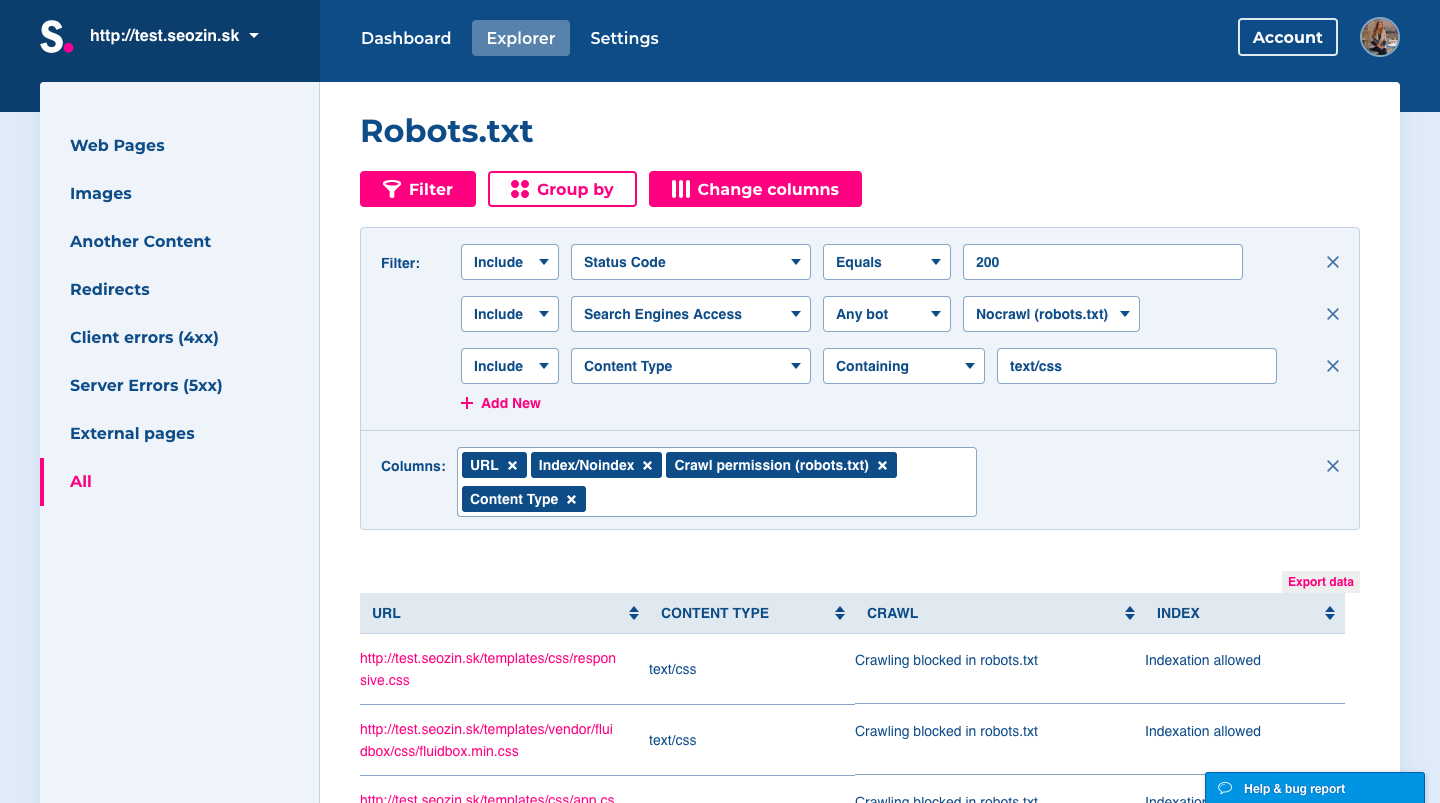
- At Dashboard, open issue CSS is blocked by robots.txt.
- In the Explorer table, you can see impacted URLs.
- For fixing this problem, you just need to enable access to CSS files in robots.txt file to web crawlers.
[box type=”download”] An example of blocked CSS in robots.txt:
Robots.txt file is located on the URL: http://yourdomain.com/robots.txt. Blocking CSS can look like this:
Disallow: /css
Or if you are running a WordPress site, you can see it like:
Disallow: /wp-admin
Disallow: /wp-includes/
Disallow: /wp-content/
In order to fix this problem, delete either /css in the source code or /wp-includes/ and /wp-content/ in the SEO section of a WordPress site.[/box]
JavaScript is blocked by robots.txt
Why does the error occur?
JavaScript files are disallowed in robots.txt file on your website.
How does it impact SEO?
Medium-high importance: ★★☆
By disallowing JavaScript in robots.txt, you can prevent search engine crawlers from rendering all the content and seeing if your website works properly. This action can be an essential problem for websites built on JavaScript. Crawlers can’t fully understand your website, and that might result in lower rankings.
How to fix it
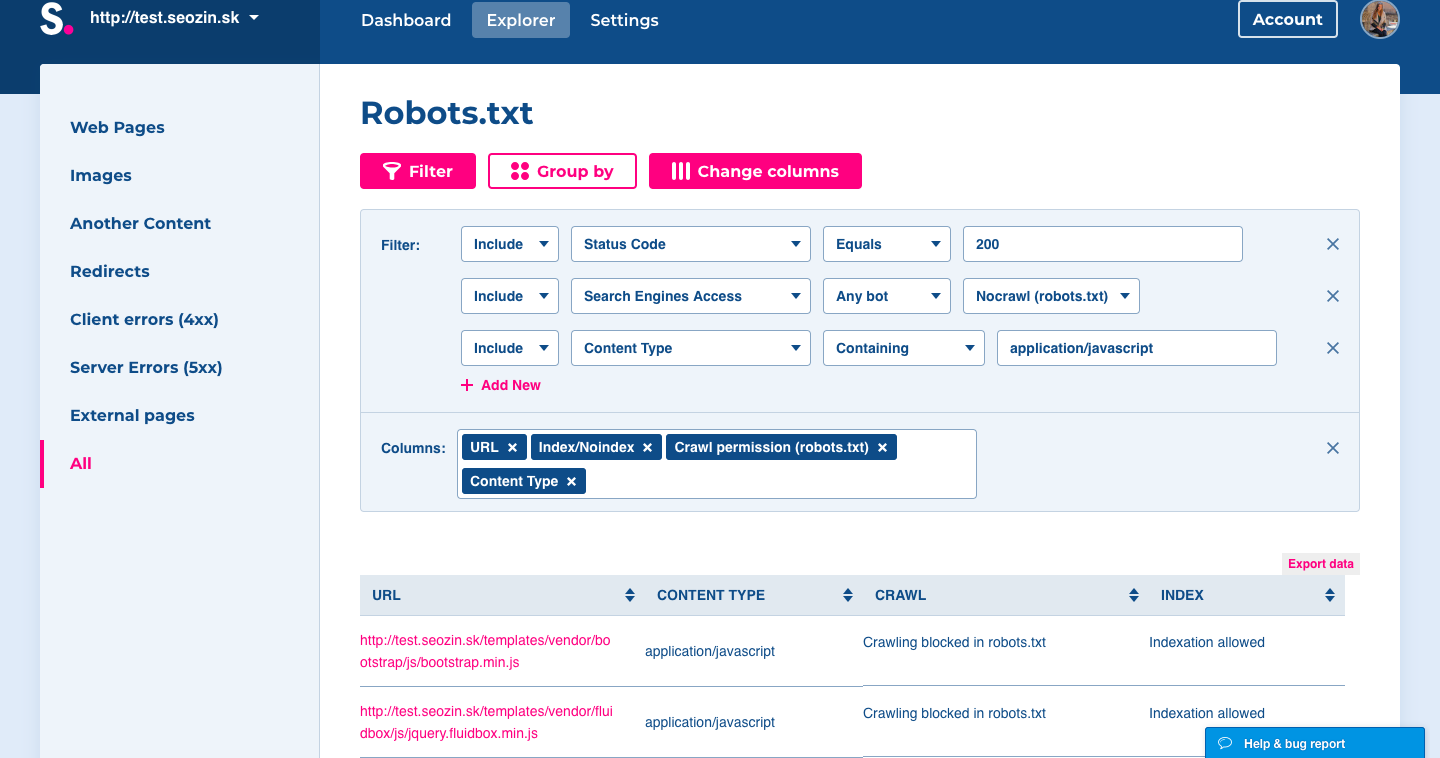
- At Dashboard, open issue JavaScript is blocked by robots.txt.
- In the Explorer table, you can see impacted URLs.
- Check to see if all of the blocked JS files don’t have an adverse influence on the page rendering. If so, you should enable access for web crawlers to access JS in robots.txt.
[box type=”download”] An example of blocked JavaScript in robots.txt:
Robots.txt file is located on the URL: http://yourdomain.com/robots.txt. Blocking JS can look like this:
Disallow: /js
Or if you are running a WordPress site, you can see it like:
Disallow: /wp-admin
Disallow: /wp-includes/
Disallow: /wp-content/
In order to fix this problem, delete either /js in the source code or /wp-includes/ and /wp-content/ in the SEO section of a WordPress site.[/box]
More technical SEO tutorials: